Welcome
Welcome to the Rollkit Specifications.
Protocol/Component Name
Abstract
Provide a concise description of the purpose of the component for which the specification is written, along with its contribution to the rollkit or other relevant parts of the system. Make sure to include proper references to the relevant sections.
Protocol/Component Description
Offer a comprehensive explanation of the protocol, covering aspects such as data flow, communication mechanisms, and any other details necessary for understanding the inner workings of this component.
Message Structure/Communication Format
If this particular component is expected to communicate over the network, outline the structure of the message protocol, including details such as field interpretation, message format, and any other relevant information.
Assumptions and Considerations
If there are any assumptions required for the component's correct operation, performance, security, or other expected features, outline them here. Additionally, provide any relevant considerations related to security or other concerns.
Implementation
Include a link to the location where the implementation of this protocol can be found. Note that specific implementation details should be documented in the rollkit repository rather than in the specification document.
References
List any references used or cited in the document.
General Tips
How to use a mermaid diagram that you can display in a markdown
sequenceDiagram
title Example
participant A
participant B
A->>B: Example
B->>A: Example
graph LR
A[Example] --> B[Example]
B --> C[Example]
C --> A
gantt
title Example
dateFormat YYYY-MM-DD
section Example
A :done, des1, 2014-01-06,2014-01-08
B :done, des2, 2014-01-06,2014-01-08
C :done, des3, 2014-01-06,2014-01-08
Grammar and spelling check
The recommendation is to use your favorite spellchecker extension in your IDE like grammarly, to make sure that the document is free of spelling and grammar errors.
Use of links
If you want to use links use proper syntax. This goes for both internal and external links like documentation or external links
At the bottom of the document in Reference, you can add the following footnotes that will be visible in the markdown document:
[1] Grammarly
[2] Documentation
[3] external links
Then at the bottom add the actual links that will not be visible in the markdown document:
Use of tables
If you are describing variables, components or other things in a structured list that can be described in a table use the following syntax:
| Name | Type | Description |
|---|---|---|
name | type | Description |
Rollkit Dependency Graph

We use the following color coding in this Graph:
- No Colour: Work not yet started
- Yellow Box: Work in progress
- Green Box: Work completed or at least unblocking the next dependency
- Red Border: Work needs to happen in cooperation with another team
If the EPICs are not linked to the box yet, it means that this box has currently no priority or is still in the ideation phase or the dependency is unclear.
Block Manager
Abstract
The block manager is a key component of full nodes and is responsible for block production or block syncing depending on the node type: sequencer or non-sequencer. Block syncing in this context includes retrieving the published blocks from the network (P2P network or DA network), validating them to raise fraud proofs upon validation failure, updating the state, and storing the validated blocks. A full node invokes multiple block manager functionalities in parallel, such as:
- Block Production (only for sequencer full nodes)
- Block Publication to DA network
- Block Retrieval from DA network
- Block Sync Service
- Block Publication to P2P network
- Block Retrieval from P2P network
- State Update after Block Retrieval
sequenceDiagram
title Overview of Block Manager
participant User
participant Sequencer
participant Full Node 1
participant Full Node 2
participant DA Layer
User->>Sequencer: Send Tx
Sequencer->>Sequencer: Generate Block
Sequencer->>DA Layer: Publish Block
Sequencer->>Full Node 1: Gossip Block
Sequencer->>Full Node 2: Gossip Block
Full Node 1->>Full Node 1: Verify Block
Full Node 1->>Full Node 2: Gossip Block
Full Node 1->>Full Node 1: Mark Block Soft Confirmed
Full Node 2->>Full Node 2: Verify Block
Full Node 2->>Full Node 2: Mark Block Soft Confirmed
DA Layer->>Full Node 1: Retrieve Block
Full Node 1->>Full Node 1: Mark Block DA Included
DA Layer->>Full Node 2: Retrieve Block
Full Node 2->>Full Node 2: Mark Block DA Included
Protocol/Component Description
The block manager is initialized using several parameters as defined below:
| Name | Type | Description |
|---|---|---|
| signing key | crypto.PrivKey | used for signing a block after it is created |
| config | config.BlockManagerConfig | block manager configurations (see config options below) |
| genesis | *cmtypes.GenesisDoc | initialize the block manager with genesis state (genesis configuration defined in config/genesis.json file under the app directory) |
| store | store.Store | local datastore for storing rollup blocks and states (default local store path is $db_dir/rollkit and db_dir specified in the config.yaml file under the app directory) |
| mempool, proxyapp, eventbus | mempool.Mempool, proxy.AppConnConsensus, *cmtypes.EventBus | for initializing the executor (state transition function). mempool is also used in the manager to check for availability of transactions for lazy block production |
| dalc | da.DAClient | the data availability light client used to submit and retrieve blocks to DA network |
| blockstore | *goheaderstore.Store[*types.Block] | to retrieve blocks gossiped over the P2P network |
Block manager configuration options:
| Name | Type | Description |
|---|---|---|
| BlockTime | time.Duration | time interval used for block production and block retrieval from block store (defaultBlockTime) |
| DABlockTime | time.Duration | time interval used for both block publication to DA network and block retrieval from DA network (defaultDABlockTime) |
| DAStartHeight | uint64 | block retrieval from DA network starts from this height |
| LazyBlockInterval | time.Duration | time interval used for block production in lazy aggregator mode even when there are no transactions (defaultLazyBlockTime) |
| LazyMode | bool | when set to true, enables lazy aggregation mode which produces blocks only when transactions are available or at LazyBlockInterval intervals |
Block Production
When the full node is operating as a sequencer (aka aggregator), the block manager runs the block production logic. There are two modes of block production, which can be specified in the block manager configurations: normal and lazy.
In normal mode, the block manager runs a timer, which is set to the BlockTime configuration parameter, and continuously produces blocks at BlockTime intervals.
In lazy mode, the block manager implements a dual timer mechanism:
- A
blockTimerthat triggers block production at regular intervals when transactions are available - A
lazyTimerthat ensures blocks are produced atLazyBlockIntervalintervals even during periods of inactivity
The block manager starts building a block when any transaction becomes available in the mempool via a notification channel (txNotifyCh). When the Reaper detects new transactions, it calls Manager.NotifyNewTransactions(), which performs a non-blocking signal on this channel. The block manager also produces empty blocks at regular intervals to maintain consistency with the DA layer, ensuring a 1:1 mapping between DA layer blocks and execution layer blocks.
Building the Block
The block manager of the sequencer nodes performs the following steps to produce a block:
- Call
CreateBlockusing executor - Sign the block using
signing keyto generate commitment - Call
ApplyBlockusing executor to generate an updated state - Save the block, validators, and updated state to local store
- Add the newly generated block to
pendingBlocksqueue - Publish the newly generated block to channels to notify other components of the sequencer node (such as block and header gossip)
Block Publication to DA Network
The block manager of the sequencer full nodes regularly publishes the produced blocks (that are pending in the pendingBlocks queue) to the DA network using the DABlockTime configuration parameter defined in the block manager config. In the event of failure to publish the block to the DA network, the manager will perform maxSubmitAttempts attempts and an exponential backoff interval between the attempts. The exponential backoff interval starts off at initialBackoff and it doubles in the next attempt and capped at DABlockTime. A successful publish event leads to the emptying of pendingBlocks queue and a failure event leads to proper error reporting without emptying of pendingBlocks queue.
Block Retrieval from DA Network
The block manager of the full nodes regularly pulls blocks from the DA network at DABlockTime intervals and starts off with a DA height read from the last state stored in the local store or DAStartHeight configuration parameter, whichever is the latest. The block manager also actively maintains and increments the daHeight counter after every DA pull. The pull happens by making the RetrieveBlocks(daHeight) request using the Data Availability Light Client (DALC) retriever, which can return either Success, NotFound, or Error. In the event of an error, a retry logic kicks in after a delay of 100 milliseconds delay between every retry and after 10 retries, an error is logged and the daHeight counter is not incremented, which basically results in the intentional stalling of the block retrieval logic. In the block NotFound scenario, there is no error as it is acceptable to have no rollup block at every DA height. The retrieval successfully increments the daHeight counter in this case. Finally, for the Success scenario, first, blocks that are successfully retrieved are marked as DA included and are sent to be applied (or state update). A successful state update triggers fresh DA and block store pulls without respecting the DABlockTime and BlockTime intervals. For more details on DA integration, see the Data Availability specification.
Out-of-Order Rollup Blocks on DA
Rollkit should support blocks arriving out-of-order on DA, like so:
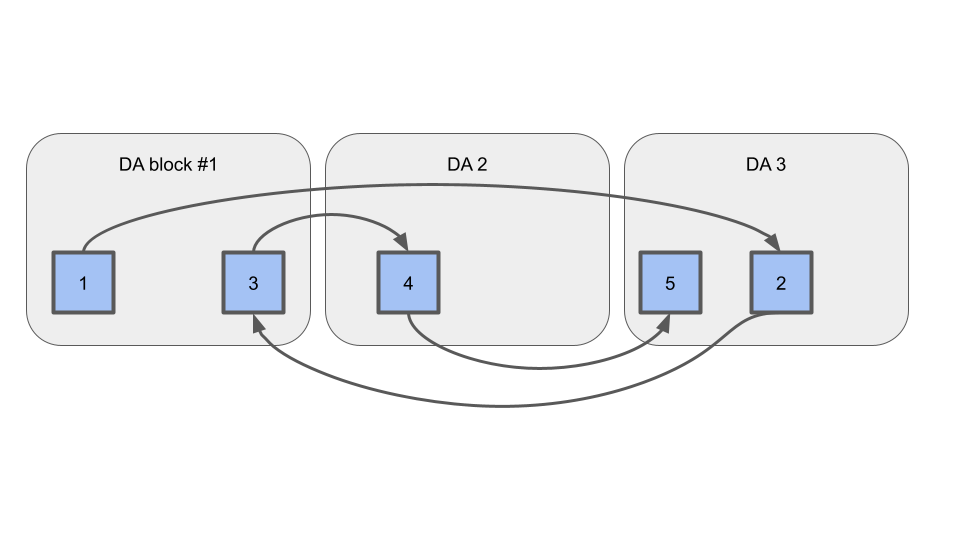
Termination Condition
If the sequencer double-signs two blocks at the same height, evidence of the fault should be posted to DA. Rollkit full nodes should process the longest valid chain up to the height of the fault evidence, and terminate. See diagram:
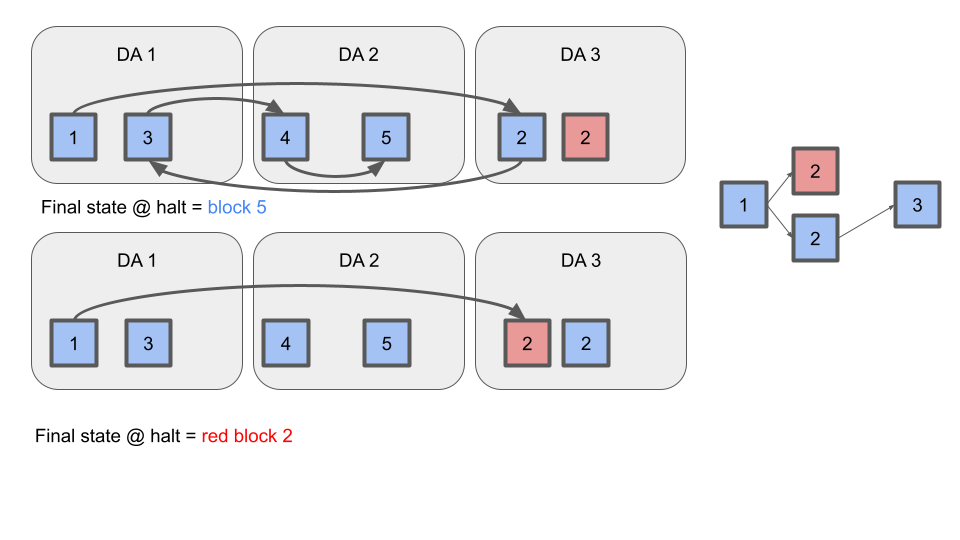
Block Sync Service
The block sync service is created during full node initialization. After that, during the block manager's initialization, a pointer to the block store inside the block sync service is passed to it. Blocks created in the block manager are then passed to the BlockCh channel and then sent to the go-header service to be gossiped blocks over the P2P network.
Block Publication to P2P network
Blocks created by the sequencer that are ready to be published to the P2P network are sent to the BlockCh channel in Block Manager inside publishLoop.
The blockPublishLoop in the full node continuously listens for new blocks from the BlockCh channel and when a new block is received, it is written to the block store and broadcasted to the network using the block sync service.
Among non-sequencer full nodes, all the block gossiping is handled by the block sync service, and they do not need to publish blocks to the P2P network using any of the block manager components.
Block Retrieval from P2P network
For non-sequencer full nodes, blocks gossiped through the P2P network are retrieved from the Block Store in BlockStoreRetrieveLoop in Block Manager.
Starting off with a block store height of zero, for every blockTime unit of time, a signal is sent to the blockStoreCh channel in the block manager and when this signal is received, the BlockStoreRetrieveLoop retrieves blocks from the block store.
It keeps track of the last retrieved block's height and every time the current block store's height is greater than the last retrieved block's height, it retrieves all blocks from the block store that are between these two heights.
For each retrieved block, it sends a new block event to the blockInCh channel which is the same channel in which blocks retrieved from the DA layer are sent.
This block is marked as soft confirmed by the validating full node until the same block data and the corresponding header is seen on the DA layer, then it is marked DA-included.
About Soft Confirmations and DA Inclusions
The block manager retrieves blocks from both the P2P network and the underlying DA network because the blocks are available in the P2P network faster and DA retrieval is slower (e.g., 1 second vs 6 seconds).
The blocks retrieved from the P2P network are only marked as soft confirmed until the DA retrieval succeeds on those blocks and they are marked DA-included.
DA-included blocks are considered to have a higher level of finality.
DAIncluderLoop:
A new loop, DAIncluderLoop, is responsible for advancing the DAIncludedHeight by checking if blocks after the current height have both their header and data marked as DA-included in the caches.
If either the header or data is missing, the loop stops advancing.
This ensures that only blocks with both header and data present are considered DA-included.
State Update after Block Retrieval
The block manager stores and applies the block to update its state every time a new block is retrieved either via the P2P or DA network. State update involves:
ApplyBlockusing executor: validates the block, executes the block (applies the transactions), captures the validator updates, and creates an updated state.Commitusing executor: commit the execution and changes, update mempool, and publish events- Store the block, the validators, and the updated state.
Message Structure/Communication Format
The communication between the block manager and executor:
InitChain: initializes the chain state with the given genesis time, initial height, and chain ID usingInitChainSyncon the executor to obtain initialappHashand initialize the state.CreateBlock: prepare a block by polling transactions from mempool.ApplyBlock: validate the block, execute the block (apply transactions), validator updates, create and return updated state.SetFinal: sets the block as final when it's corresponding header and data are seen on the dA layer.
Assumptions and Considerations
- The block manager loads the initial state from the local store and uses genesis if not found in the local store, when the node (re)starts.
- The default mode for sequencer nodes is normal (not lazy).
- The sequencer can produce empty blocks.
- In lazy aggregation mode, the block manager maintains consistency with the DA layer by producing empty blocks at regular intervals, ensuring a 1:1 mapping between DA layer blocks and execution layer blocks.
- The lazy aggregation mechanism uses a dual timer approach:
- A
blockTimerthat triggers block production when transactions are available - A
lazyTimerthat ensures blocks are produced even during periods of inactivity
- A
- Empty batches are handled differently in lazy mode - instead of discarding them, they are returned with the
ErrNoBatcherror, allowing the caller to create empty blocks with proper timestamps. - Transaction notifications from the
Reaperto theManagerare handled via a non-blocking notification channel (txNotifyCh) to prevent backpressure. - The block manager uses persistent storage (disk) when the
root_diranddb_pathconfiguration parameters are specified inconfig.yamlfile under the app directory. If these configuration parameters are not specified, the in-memory storage is used, which will not be persistent if the node stops. - The block manager does not re-apply the block again (in other words, create a new updated state and persist it) when a block was initially applied using P2P block sync, but later was DA included during DA retrieval. The block is only marked DA included in this case.
- The data sync store is created by prefixing
dataSyncon the main data store. - The genesis
ChainIDis used to create thePubSubTopIDin go-header with the string-blockappended to it. This append is because the full node also has a P2P header sync running with a different P2P network. Refer to go-header specs for more details. - Block sync over the P2P network works only when a full node is connected to the P2P network by specifying the initial seeds to connect to via
P2PConfig.Seedsconfiguration parameter when starting the full node. - Node's context is passed down to all the components of the P2P block sync to control shutting down the service either abruptly (in case of failure) or gracefully (during successful scenarios).
- The block manager supports the separation of header and data structures in Rollkit. This allows for expanding the sequencing scheme beyond single sequencing and enables the use of a decentralized sequencer mode. For detailed information on this architecture, see the Header and Data Separation ADR.
- The block manager processes blocks with a minimal header format, which is designed to eliminate dependency on CometBFT's header format and can be used to produce an execution layer tailored header if needed. For details on this header structure, see the Rollkit Minimal Header specification.
Implementation
See block-manager
See tutorial for running a multi-node network with both sequencer and non-sequencer full nodes.
References
[1] Go Header
[2] Block Sync
[3] Full Node
[4] Block Manager
[5] Tutorial
[6] Header and Data Separation ADR
[9] Lazy Aggregation with DA Layer Consistency ADR
Block and Header Validity
Abstract
Like all blockchains, rollups are defined as the chain of valid blocks from the genesis, to the head. Thus, the block and header validity rules define the chain.
Verifying a block/header is done in 3 parts:
-
Verify correct serialization according to the protobuf spec
-
Perform basic validation of the types
-
Perform verification of the new block against the previously accepted block
Basic Validation
Each type contains a .ValidateBasic() method, which verifies that certain basic invariants hold. The ValidateBasic() calls are nested, starting from the Block struct, all the way down to each subfield.
The nested basic validation, and validation checks, are called as follows:
Block.ValidateBasic()
// Make sure the block's SignedHeader passes basic validation
SignedHeader.ValidateBasic()
// Make sure the SignedHeader's Header passes basic validation
Header.ValidateBasic()
verify ProposerAddress not nil
// Make sure the SignedHeader's signature passes basic validation
Signature.ValidateBasic()
// Ensure that someone signed the block
verify len(c.Signatures) not 0
If sh.Validators is nil, or len(sh.Validators.Validators) is 0, assume based rollup, pass validation, and skip all remaining checks.
Validators.ValidateBasic()
// github.com/rollkit/cometbft/blob/main/types/validator.go#L37
verify sh.Validators is not nil, and len(sh.Validators.Validators) != 0
// apply basic validation to all Validators
for each validator:
validator.ValidateBasic()
validate not nil
validator.PubKey not nil
validator.Address == correct size
// apply ValidateBasic to the proposer field:
sh.Validators.Proposer.ValidateBasic()
validate not nil
validator.PubKey not nil
validator.Address == correct size
Assert that SignedHeader.Validators.Hash() == SignedHeader.AggregatorsHash
Verify SignedHeader.Signature
Data.ValidateBasic() // always passes
// make sure the SignedHeader's DataHash is equal to the hash of the actual data in the block.
Data.Hash() == SignedHeader.DataHash
Verification Against Previous Block
// code does not match spec: see https://github.com/rollkit/rollkit/issues/1277
Block.Verify()
SignedHeader.Verify(untrustH *SignedHeader)
// basic validation removed in #1231, because go-header already validates it
//untrustH.ValidateBasic()
Header.Verify(untrustH *SignedHeader)
if untrustH.Height == h.Height + 1, then apply the following check:
untrstH.AggregatorsHash[:], h.NextAggregatorsHash[:]
if untrustH.Height > h.Height + 1:
soft verification failure
// We should know they're adjacent now,
// verify the link to previous.
untrustH.LastHeaderHash == h.Header.Hash()
// Verify LastCommit hash
untrustH.LastCommitHash == sh.Signature.GetCommitHash(...)
Data
| Field Name | Valid State | Validation |
|---|---|---|
| Data | Transaction data of the block | Data.Hash == SignedHeader.DataHash |
SignedHeader
| Field Name | Valid State | Validation |
|---|---|---|
| Header | Valid header for the block | Header passes ValidateBasic() and Verify() |
| Signature | 1 valid signature from the single sequencer | Signature passes ValidateBasic(), with additional checks in SignedHeader.ValidateBasic() |
| Validators | Array of Aggregators, must have length exactly 1. | Validators passes ValidateBasic() |
Header
Note: The AggregatorsHash and NextAggregatorsHash fields have been removed. Rollkit vA should ignore all Valset updates from the ABCI app, and always enforce that the proposer is the single sequencer set as the 1 validator in the genesis block.
| Field Name | Valid State | Validation |
|---|---|---|
| BaseHeader . | ||
| Height | Height of the previous accepted header, plus 1. | checked in the `Verify()`` step |
| Time | Timestamp of the block | Not validated in Rollkit |
| ChainID | The hard-coded ChainID of the chain | Should be checked as soon as the header is received |
| Header . | ||
| Version | unused | |
| LastHeaderHash | The hash of the previous accepted block | checked in the `Verify()`` step |
| LastCommitHash | The hash of the previous accepted block's commit | checked in the `Verify()`` step |
| DataHash | Correct hash of the block's Data field | checked in the `ValidateBasic()`` step |
| ConsensusHash | unused | |
| AppHash | The correct state root after executing the block's transactions against the accepted state | checked during block execution |
| LastResultsHash | Correct results from executing transactions | checked during block execution |
| ProposerAddress | Address of the expected proposer | checked in the Verify() step |
| Signature | Signature of the expected proposer | signature verification occurs in the ValidateBasic() step |
ValidatorSet
| Field Name | Valid State | Validation |
|---|---|---|
| Validators | Array of validators, each must pass Validator.ValidateBasic() | Validator.ValidateBasic() |
| Proposer | Must pass Validator.ValidateBasic() | Validator.ValidateBasic() |
DA
Rollkit provides a wrapper for go-da, a generic data availability interface for modular blockchains, called DAClient with wrapper functionalities like SubmitBlocks and RetrieveBlocks to help block manager interact with DA more easily.
Details
DAClient can connect via either gRPC or JSON-RPC transports using the go-da proxy/grpc or proxy/jsonrpc implementations. The connection can be configured using the following cli flags:
--rollkit.da_address: url address of the DA service (default: "grpc://localhost:26650")--rollkit.da_auth_token: authentication token of the DA service--rollkit.da_namespace: namespace to use when submitting blobs to the DA service
Given a set of blocks to be submitted to DA by the block manager, the SubmitBlocks first encodes the blocks using protobuf (the encoded data are called blobs) and invokes the Submit method on the underlying DA implementation. On successful submission (StatusSuccess), the DA block height which included in the blocks is returned.
To make sure that the serialised blocks don't exceed the underlying DA's blob limits, it fetches the blob size limit by calling Config which returns the limit as uint64 bytes, then includes serialised blocks until the limit is reached. If the limit is reached, it submits the partial set and returns the count of successfully submitted blocks as SubmittedCount. The caller should retry with the remaining blocks until all the blocks are submitted. If the first block itself is over the limit, it throws an error.
The Submit call may result in an error (StatusError) based on the underlying DA implementations on following scenarios:
- the total blobs size exceeds the underlying DA's limits (includes empty blobs)
- the implementation specific failures, e.g., for celestia-da-json-rpc, invalid namespace, unable to create the commitment or proof, setting low gas price, etc, could return error.
The RetrieveBlocks retrieves the blocks for a given DA height using go-da GetIDs and Get methods. If there are no blocks available for a given DA height, StatusNotFound is returned (which is not an error case). The retrieved blobs are converted back to blocks and returned on successful retrieval.
Both SubmitBlocks and RetrieveBlocks may be unsuccessful if the DA node and the DA blockchain that the DA implementation is using have failures. For example, failures such as, DA mempool is full, DA submit transaction is nonce clashing with other transaction from the DA submitter account, DA node is not synced, etc.
Implementation
References
[1] go-da
[2] proxy/grpc
[3] proxy/jsonrpc
Full Node
Abstract
A Full Node is a top-level service that encapsulates different components of Rollkit and initializes/manages them.
Details
Full Node Details
A Full Node is initialized inside the Cosmos SDK start script along with the node configuration, a private key to use in the P2P client, a private key for signing blocks as a block proposer, a client creator, a genesis document, and a logger. It uses them to initialize the components described above. The components TxIndexer, BlockIndexer, and IndexerService exist to ensure cometBFT compatibility since they are needed for most of the RPC calls from the SignClient interface from cometBFT.
Note that unlike a light node which only syncs and stores block headers seen on the P2P layer, the full node also syncs and stores full blocks seen on both the P2P network and the DA layer. Full blocks contain all the transactions published as part of the block.
The Full Node mainly encapsulates and initializes/manages the following components:
genesisDoc
The genesis document contains information about the initial state of the chain, in particular its validator set.
conf
The node configuration contains all the necessary settings for the node to be initialized and function properly.
P2P
The peer-to-peer client is used to gossip transactions between full nodes in the network.
Store
The Store is initialized with DefaultStore, an implementation of the store interface which is used for storing and retrieving blocks, commits, and state. |
blockManager
The Block Manager is responsible for managing the operations related to blocks such as creating and validating blocks.
dalc
The Data Availability Layer Client is used to interact with the data availability layer. It is initialized with the DA Layer and DA Config specified in the node configuration.
hExService
The Header Sync Service is used for syncing block headers between nodes over P2P.
bSyncService
The Block Sync Service is used for syncing blocks between nodes over P2P.
Message Structure/Communication Format
The Full Node communicates with other nodes in the network using the P2P client. It also communicates with the application using the ABCI proxy connections. The communication format is based on the P2P and ABCI protocols.
Assumptions and Considerations
The Full Node assumes that the configuration, private keys, client creator, genesis document, and logger are correctly passed in by the Cosmos SDK. It also assumes that the P2P client, data availability layer client, block manager, and other services can be started and stopped without errors.
Implementation
See full node
References
[1] Full Node
[2] Genesis Document
[5] Store
[6] Store Interface
[7] Block Manager
[8] Data Availability Layer Client
[10] Block Sync Service
Header Sync
Abstract
The nodes in the P2P network sync headers using the header sync service that implements the go-header interface. The header sync service consists of several components as listed below.
| Component | Description |
|---|---|
| store | a headerEx prefixed datastore where synced headers are stored |
| subscriber | a libp2p node pubsub subscriber |
| P2P server | a server for handling header requests between peers in the P2P network |
| exchange | a client that enables sending in/out-bound header requests from/to the P2P network |
| syncer | a service for efficient synchronization for headers. When a P2P node falls behind and wants to catch up to the latest network head via P2P network, it can use the syncer. |
Details
All three types of nodes (sequencer, full, and light) run the header sync service to maintain the canonical view of the chain (with respect to the P2P network).
The header sync service inherits the ConnectionGater from the node's P2P client which enables blocking and allowing peers as needed by specifying the P2PConfig.BlockedPeers and P2PConfig.AllowedPeers.
NodeConfig.BlockTime is used to configure the syncer such that it can effectively decide the outdated headers while it receives headers from the P2P network.
Both header and block sync utilizes go-header library and runs two separate sync services, for the headers and blocks. This distinction is mainly to serve light nodes which do not store blocks, but only headers synced from the P2P network.
Consumption of Header Sync
The sequencer node, upon successfully creating the block, publishes the signed block header to the P2P network using the header sync service. The full/light nodes run the header sync service in the background to receive and store the signed headers from the P2P network. Currently the full/light nodes do not consume the P2P synced headers, however they have future utilities in performing certain checks.
Assumptions
- The header sync store is created by prefixing
headerSyncthe main datastore. - The genesis
ChainIDis used to create thePubsubTopicIDin go-header. For example, for ChainIDgm, the pubsub topic id is/gm/header-sub/v0.0.1. Refer to go-header specs for further details. - The header store must be initialized with genesis header before starting the syncer service. The genesis header can be loaded by passing the genesis header hash via
NodeConfig.TrustedHashconfiguration parameter or by querying the P2P network. This imposes a time constraint that full/light nodes have to wait for the sequencer to publish the genesis header to the P2P network before starting the header sync service. - The Header Sync works only when the node is connected to the P2P network by specifying the initial seeds to connect to via the
P2PConfig.Seedsconfiguration parameter. - The node's context is passed down to all the components of the P2P header sync to control shutting down the service either abruptly (in case of failure) or gracefully (during successful scenarios).
Implementation
The header sync implementation can be found in block/sync_service.go. The full and light nodes create and start the header sync service under full and light.
References
[1] Header Sync
[2] Full Node
[3] Light Node
[4] go-header
Header and Data Separation ADR
Abstract
The separation of header and data structures in Rollkit unlocks expanding the sequencing scheme beyond single sequencing and unlocks the use of a decentralized sequencer mode. This means that the creation of list of the transactions can be done by another network as well while nodes still produce headers after executing that list of transactions. This overall change is akin to the proposer-builder separation in the Ethereum protocol, where the Rollkit header producer acts as the proposer, and the sequencer, which produces a list of transactions, acts as the builder.
Before Separation
flowchart LR
CS[Single Sequencer] -->|Creates| B[Block]
B -->|Contains| SH1[SignedHeader]
B -->|Contains| D1[Data]
class CS,B,SH1,D1 node
After Separation
flowchart LR
HP[Header Producer] -->|Creates| SH2[SignedHeader]
SEQ[Sequencer] -->|Creates| D2[Data]
SH2 -.->|References via DataCommitment| D2
class HP,SEQ,SH2,D2 node
Protocol/Component Description
Before, Rollkit only supported the use of a single sequencer that was responsible for creating a list of transactions by reaping its mempool, executing them to produce a header, and putting them together in a block. Rollkit headers and data were encapsulated within a single block structure. The block struct looked like this:
// Block defines the structure of Rollkit block.
type Block struct {
SignedHeader SignedHeader
Data Data
}
The separation of header and data into distinct structures allows them to be processed independently. The SignedHeader struct now focuses on the header information, while the Data struct handles transaction data separately. This separation is particularly beneficial in unlocking based sequencing, where users submit transactions directly to the Data Availability layer which acts as the entity responsible for creating the list of transactions.
classDiagram
class Block {
SignedHeader
Data
}
class SignedHeader {
Header
Signature
}
class Header {
ParentHash
Height
Timestamp
ChainID
DataCommitment
StateRoot
ExtraData
}
class Data {
Metadata
Txs
}
Block *-- SignedHeader
Block *-- Data
SignedHeader *-- Header
This change also affects how full nodes sync. Previously, full nodes would apply the transactions from the Block struct and verify that the header in SignedHeader matched their locally produced header. Now, with the separation, full nodes obtain the transaction data separately (via the DA layer directly in based sequencer mode, or via p2p gossip/DA layer in single sequencer mode) and verify it against the header signed by the header producer once they have both components. If a full node receives the header/data via a p2p gossip layer, they should wait to see the same header/data on the DA layer before marking the corresponding block as finalized in their view.
This ensures that the data integrity and consistency are maintained across the network.
// SignedHeader struct consists of the header and a signature
type SignedHeader struct {
Header // Rollkit Header
Signature Signature // Signature of the header producer
...
}
// Header struct focusing on header information
type Header struct {
// Hash of the previous block header.
ParentHash Hash
// Height represents the block height (aka block number) of a given header
Height uint64
// Block creation timestamp
Timestamp uint64
// The Chain ID
ChainID string
// Pointer to location of associated block data aka transactions in the DA layer
DataCommitment Hash
// Commitment representing the state linked to the header
StateRoot Hash
// Arbitrary field for additional metadata
ExtraData []byte
}
// Data defines Rollkit block data.
type Data struct {
*Metadata // Defines metadata for Data struct to help with p2p gossiping.
Txs Txs // List of transactions to be executed
}
The publishBlock method in manager.go now creates the header and data structures separately. This decoupling allows for the header to be submitted to the DA layer independently of the block data, which can be built by a separate network. This change supports the transition from a single sequencer mode to a decentralized sequencer mode, making the system more modular.
Message Structure/Communication Format
Header Producer
Before the separation: Only the entire Block struct composed of both header and data was submitted to the DA layer. The Block and SignedHeader were both gossipped over two separate p2p layers: gossipping Block to just full nodes and gossipping the SignedHeader to full nodes and future light nodes to join that will only sync headers (and proofs).
After the separation: The SignedHeader and Data are submitted separately to the DA layer. Note that the SignedHeader has a Header that is linked to the Data via a DataCommitment from the DA layer. SignedHeader and Data are both gossipped over two separate p2p layers: gossipping Data to just full nodes and gossipping the SignedHeader to full nodes and future light nodes to join that will only sync headers (and proofs).
In based sequencing mode, the header producer is equivalent to a full node.
Before Separation
flowchart LR
CS1[Single Sequencer] -->|Submits Block| DA1[DA Layer]
CS1 -->|Gossips Block| FN1[Full Nodes]
CS1 -->|Gossips SignedHeader| LN1[Light Nodes]
class CS1,DA1,FN1,LN1 node
After Separation - Single Sequencer Mode
flowchart LR
CS2[Single Sequencer] -->|Submits Data| DA2[DA Layer]
HP2[Header Producer] -->|Submits SignedHeader| DA2
CS2 -->|Gossips Data| FN2[Full Nodes]
HP2 -->|Gossips SignedHeader| FN2
HP2 -->|Gossips SignedHeader| LN2[Light Nodes]
class CS2,HP2,DA2,FN2,LN2 node
After Separation - Based Mode
flowchart LR
Users -->|Submit Txs| DA3[DA Layer]
FN3[Full Node/Header Producer] -->|Reads Data| DA3
class Users,DA3,FN3,LN3 node
Syncing Full Node
Before the separation: Full Nodes get the entire Block struct via p2p or the DA layer. They can choose to apply the block as soon as they get it via p2p OR just wait to see it on the DA layer. This depends on whether a full node opts in to the p2p layer or not. Gossipping the SignedHeader over p2p is primarily for light nodes to get the header.
After the separation: Full nodes get the Data struct and the SignedHeader struct separately over p2p and DA layers. In code, this refers to the HeaderStore and the DataStore in block manager. A Full node should wait for having both the Data struct and the corresponding SignedHeader to it before applying the block data to its associated state machine. This is so that the full node can verify that its locally produced header's state commitment after it applies the Data associated to a block is consistent with the Header inside the SignedHeader that is received from the header producer. The Header should contain a link to its associated Data via a DataCommitment that is a pointer to the location of the Data on the DA layer.
sequenceDiagram
participant FN as Full Node
participant P2P as P2P Network
participant DA as DA Layer
participant SM as State Machine
Note over FN,DA: After Separation - Sync Process
P2P->>FN: Receive Data
P2P->>FN: Receive SignedHeader
FN->>DA: Verify Data availability
FN->>DA: Verify SignedHeader availability
FN->>FN: Match Data with SignedHeader via DataCommitment
FN->>SM: Apply Data to state machine
FN->>FN: Verify locally produced header matches received Header
FN->>FN: Mark block as finalized
In a single sequencer mode, before, a full node marks a block finalized, it should verify that both the SignedHeader and Data associated to it were made available on the DA layer by checking it directly or verifying DA inclusion proofs.
In based sequencing mode, blocks can be instantly finalized since the Data is directly always derived from the DA layer and already exists there. There's no need for a SignedHeader to exist on the DA layer.
sequenceDiagram
participant DA as DA Layer
participant FN as Full Node
participant SM as State Machine
Note over DA,FN: Based Sequencing Mode
DA->>FN: Data already available
FN->>FN: Read Data from DA
FN->>FN: Execute transactions
FN->>FN: Produce Header
FN->>SM: Apply state changes
FN->>FN: Finalize Block
Note right of FN: No need to submit SignedHeader to DA
Assumptions and Considerations
- Considerations include ensuring that headers and data are correctly synchronized and validated to prevent inconsistencies.
- Ensure that all components interacting with headers and data are updated to handle them as separate entities.
- Security measures should be in place to prevent unauthorized access or tampering with headers and data during transmission and storage.
- Performance optimizations may be necessary to handle the increased complexity of managing separate header and data structures, especially in high-throughput environments.
- Testing and validation processes should be updated to account for the new structure and ensure that all components function correctly in both single and decentralized sequencer modes.
Implementation
The implementation of this separation can be found in the Rollkit repository, specifically in the changes made to the manager.go file. The publishBlock method illustrates the creation of separate header and data structures, and the associated logic for handling them independently. See Rollkit PR #1789
References
Rollkit Minimal Header
Abstract
This document specifies a minimal header format for Rollkit, designed to eliminate the dependency on CometBFT's header format. This new format can then be used to produce an execution layer tailored header if needed. For example, the new ABCI Execution layer can have an ABCI-specific header for IBC compatibility. This allows Rollkit to define its own header structure while maintaining backward compatibility where necessary.
Protocol/Component Description
The Rollkit minimal header is a streamlined version of the traditional header, focusing on essential information required for block processing and state management for nodes. This header format is designed to be lightweight and efficient, facilitating faster processing and reduced overhead.
Rollkit Minimal Header Structure
┌─────────────────────────────────────────────┐
│ Rollkit Minimal Header │
├─────────────────────┬───────────────────────┤
│ ParentHash │ Hash of previous block│
├─────────────────────┼───────────────────────┤
│ Height │ Block number │
├─────────────────────┼───────────────────────┤
│ Timestamp │ Creation time │
├─────────────────────┼───────────────────────┤
│ ChainID │ Chain identifier │
├─────────────────────┼───────────────────────┤
│ DataCommitment │ Pointer to block data │
│ │ on DA layer │
├─────────────────────┼───────────────────────┤
│ StateRoot │ State commitment │
├─────────────────────┼───────────────────────┤
│ ExtraData │ Additional metadata │
│ │ (e.g. sequencer info) │
└─────────────────────┴───────────────────────┘
Message Structure/Communication Format
The header is defined in GoLang as follows:
// Header struct focusing on header information
type Header struct {
// Hash of the previous block header.
ParentHash Hash
// Height represents the block height (aka block number) of a given header
Height uint64
// Block creation timestamp
Timestamp uint64
// The Chain ID
ChainID string
// Pointer to location of associated block data aka transactions in the DA layer
DataCommitment []byte
// Commitment representing the state linked to the header
StateRoot Hash
// Arbitrary field for additional metadata
ExtraData []byte
}
In case the chain has a specific designated proposer or a proposer set, that information can be put in the extraData field. So in single sequencer mode, the sequencerAddress can live in extraData. For base sequencer mode, this information is not relevant.
This minimal Rollkit header can be transformed to be tailored to a specific execution layer as well by inserting additional information typically needed.
EVM execution client
transactionsRoot: Merkle root of all transactions in the block. Can be constructed from unpacking theDataCommitmentin Rollkit Header.receiptsRoot: Merkle root of all transaction receipts, which store the results of transaction execution. This can be inserted by the EVM execution client.Gas Limit: Max gas allowed in the block.Gas Used: Total gas consumed in this block.
Transformation to EVM Header
┌─────────────────────────────────────────────┐
│ Rollkit Minimal Header │
└───────────────────┬─────────────────────────┘
│
▼ Transform
┌─────────────────────────────────────────────┐
│ EVM Header │
├─────────────────────┬───────────────────────┤
│ ParentHash │ From Rollkit Header │
├─────────────────────┼───────────────────────┤
│ Height/Number │ From Rollkit Header │
├─────────────────────┼───────────────────────┤
│ Timestamp │ From Rollkit Header │
├─────────────────────┼───────────────────────┤
│ ChainID │ From Rollkit Header │
├─────────────────────┼───────────────────────┤
│ TransactionsRoot │ Derived from │
│ │ DataCommitment │
├─────────────────────┼───────────────────────┤
│ StateRoot │ From Rollkit Header │
├─────────────────────┼───────────────────────┤
│ ReceiptsRoot │ Added by EVM client │
├─────────────────────┼───────────────────────┤
│ GasLimit │ Added by EVM client │
├─────────────────────┼───────────────────────┤
│ GasUsed │ Added by EVM client │
├─────────────────────┼───────────────────────┤
│ ExtraData │ From Rollkit Header │
└─────────────────────┴───────────────────────┘
ABCI Execution
This header can be transformed into an ABCI-specific header for IBC compatibility.
Version: Required by IBC clients to correctly interpret the block's structure and contents.LastCommitHash: The hash of the previous block's commit, used by IBC clients to verify the legitimacy of the block's state transitions.DataHash: A hash of the block's transaction data, enabling IBC clients to verify that the data has not been tampered with. Can be constructed from unpacking theDataCommitmentin Rollkit header.ValidatorHash: Current validator set's hash, which IBC clients use to verify that the block was validated by the correct set of validators. This can be the IBC attester set of the chain for backward compatibility with the IBC Tendermint client, if needed.NextValidatorsHash: The hash of the next validator set, allowing IBC clients to anticipate and verify upcoming validators.ConsensusHash: Denotes the hash of the consensus parameters, ensuring that IBC clients are aligned with the consensus rules of the blockchain.AppHash: Same as theStateRootin the Rollkit Header.EvidenceHash: A hash of evidence of any misbehavior by validators, which IBC clients use to assess the trustworthiness of the validator set.LastResultsHash: Root hash of all results from the transactions from the previous block.ProposerAddress: The address of the block proposer, allowing IBC clients to track and verify the entities proposing new blocks. Can be constructed from theextraDatafield in the Rollkit Header.
Transformation to ABCI Header
┌─────────────────────────────────────────────┐
│ Rollkit Minimal Header │
└───────────────────┬─────────────────────────┘
│
▼ Transform
┌─────────────────────────────────────────────┐
│ ABCI Header │
├─────────────────────┬───────────────────────┤
│ Height │ From Rollkit Header │
├─────────────────────┼───────────────────────┤
│ Time │ From Rollkit Header │
├─────────────────────┼───────────────────────┤
│ ChainID │ From Rollkit Header │
├─────────────────────┼───────────────────────┤
│ AppHash │ From StateRoot │
├─────────────────────┼───────────────────────┤
│ DataHash │ From DataCommitment │
├─────────────────────┼───────────────────────┤
│ Version │ Added for IBC │
├─────────────────────┼───────────────────────┤
│ LastCommitHash │ Added for IBC │
├─────────────────────┼───────────────────────┤
│ ValidatorHash │ Added for IBC │
├─────────────────────┼───────────────────────┤
│ NextValidatorsHash │ Added for IBC │
├─────────────────────┼───────────────────────┤
│ ConsensusHash │ Added for IBC │
├─────────────────────┼───────────────────────┤
│ EvidenceHash │ Added for IBC │
├─────────────────────┼───────────────────────┤
│ LastResultsHash │ Added for IBC │
├─────────────────────┼───────────────────────┤
│ ProposerAddress │ From ExtraData │
└─────────────────────┴───────────────────────┘
Assumptions and Considerations
- The Rollkit minimal header is designed to be flexible and adaptable, allowing for integration with various execution layers such as EVM and ABCI, without being constrained by CometBFT's header format.
- The
extraDatafield provides a mechanism for including additional metadata, such as sequencer information, which can be crucial for certain chain configurations. - The transformation of the Rollkit header into execution layer-specific headers should be done carefully to ensure compatibility and correctness, especially for IBC and any other cross-chain communication protocols.
Header Transformation Flow
┌─────────────────────────────────────────────┐
│ Rollkit Minimal Header │
│ │
│ A lightweight, flexible header format │
│ with essential fields for block processing │
└───────────┬─────────────────┬───────────────┘
│ │
▼ ▼
┌───────────────────┐ ┌─────────────────────┐
│ EVM Header │ │ ABCI Header │
│ │ │ │
│ For EVM-based │ │ For IBC-compatible │
│ execution layers │ │ execution layers │
└───────────────────┘ └─────────────────────┘
Implementation
Pending implementation.
References
- Ethereum Developer Documentation: Comprehensive resources for understanding Ethereum's architecture, including block and transaction structures.
- Tendermint Core Documentation: Detailed documentation on Tendermint, which includes information on ABCI and its header format.
- ABCI Specification: The official specification for the Application Blockchain Interface (ABCI), which describes how applications can interact with the Tendermint consensus engine.
- IBC Protocol Specification: Documentation on the Inter-Blockchain Communication (IBC) protocol, which includes details on how headers are used for cross-chain communication.
P2P
Every node (both full and light) runs a P2P client using go-libp2p P2P networking stack for gossiping transactions in the chain's P2P network. The same P2P client is also used by the header and block sync services for gossiping headers and blocks.
Following parameters are required for creating a new instance of a P2P client:
- P2PConfig (described below)
- go-libp2p private key used to create a libp2p connection and join the p2p network.
- chainID: identifier used as namespace within the p2p network for peer discovery. The namespace acts as a sub network in the p2p network, where peer connections are limited to the same namespace.
- datastore: an instance of go-datastore used for creating a connection gator and stores blocked and allowed peers.
- logger
// P2PConfig stores configuration related to peer-to-peer networking.
type P2PConfig struct {
ListenAddress string // Address to listen for incoming connections
Seeds string // Comma separated list of seed nodes to connect to
BlockedPeers string // Comma separated list of nodes to ignore
AllowedPeers string // Comma separated list of nodes to whitelist
}
A P2P client also instantiates a connection gator to block and allow peers specified in the P2PConfig.
It also sets up a gossiper using the gossip topic <chainID>+<txTopicSuffix> (txTopicSuffix is defined in p2p/client.go), a Distributed Hash Table (DHT) using the Seeds defined in the P2PConfig and peer discovery using go-libp2p's discovery.RoutingDiscovery.
A P2P client provides an interface SetTxValidator(p2p.GossipValidator) for specifying a gossip validator which can define how to handle the incoming GossipMessage in the P2P network. The GossipMessage represents message gossiped via P2P network (e.g. transaction, Block etc).
// GossipValidator is a callback function type.
type GossipValidator func(*GossipMessage) bool
The full nodes define a transaction validator (shown below) as gossip validator for processing the gossiped transactions to add to the mempool, whereas light nodes simply pass a dummy validator as light nodes do not process gossiped transactions.
// newTxValidator creates a pubsub validator that uses the node's mempool to check the
// transaction. If the transaction is valid, then it is added to the mempool
func (n *FullNode) newTxValidator() p2p.GossipValidator {
// Dummy validator that always returns a callback function with boolean `false`
func (ln *LightNode) falseValidator() p2p.GossipValidator {
References
[1] client.go
[2] go-datastore
[3] go-libp2p
[4] conngater
Store
Abstract
The Store interface defines methods for storing and retrieving blocks, commits, and the state of the blockchain.
Protocol/Component Description
The Store interface defines the following methods:
Height: Returns the height of the highest block in the store.SetHeight: Sets given height in the store if it's higher than the existing height in the store.SaveBlock: Saves a block along with its seen signature.GetBlock: Returns a block at a given height.GetBlockByHash: Returns a block with a given block header hash.SaveBlockResponses: Saves block responses in the Store.GetBlockResponses: Returns block results at a given height.GetSignature: Returns a signature for a block at a given height.GetSignatureByHash: Returns a signature for a block with a given block header hash.UpdateState: Updates the state saved in the Store. Only one State is stored.GetState: Returns the last state saved with UpdateState.SaveValidators: Saves the validator set at a given height.GetValidators: Returns the validator set at a given height.
The TxnDatastore interface inside go-datastore is used for constructing different key-value stores for the underlying storage of a full node. The are two different implementations of TxnDatastore in kv.go:
-
NewDefaultInMemoryKVStore: Builds a key-value store that uses the BadgerDB library and operates in-memory, without accessing the disk. Used only across unit tests and integration tests. -
NewDefaultKVStore: Builds a key-value store that uses the BadgerDB library and stores the data on disk at the specified path.
A Rollkit full node is initialized using NewDefaultKVStore as the base key-value store for underlying storage. To store various types of data in this base key-value store, different prefixes are used: mainPrefix, dalcPrefix, and indexerPrefix. The mainPrefix equal to 0 is used for the main node data, dalcPrefix equal to 1 is used for Data Availability Layer Client (DALC) data, and indexerPrefix equal to 2 is used for indexing related data.
For the main node data, DefaultStore struct, an implementation of the Store interface, is used with the following prefixes for various types of data within it:
blockPrefixwith value "b": Used to store blocks in the key-value store.indexPrefixwith value "i": Used to index the blocks stored in the key-value store.commitPrefixwith value "c": Used to store commits related to the blocks.statePrefixwith value "s": Used to store the state of the blockchain.responsesPrefixwith value "r": Used to store responses related to the blocks.validatorsPrefixwith value "v": Used to store validator sets at a given height.
For example, in a call to GetBlockByHash for some block hash <block_hash>, the key used in the full node's base key-value store will be /0/b/<block_hash> where 0 is the main store prefix and b is the block prefix. Similarly, in a call to GetValidators for some height <height>, the key used in the full node's base key-value store will be /0/v/<height> where 0 is the main store prefix and v is the validator set prefix.
Inside the key-value store, the value of these various types of data like Block is stored as a byte array which is encoded and decoded using the corresponding Protobuf marshal and unmarshal methods.
The store is most widely used inside the block manager to perform their functions correctly. Within the block manager, since it has multiple go-routines in it, it is protected by a mutex lock, lastStateMtx, to synchronize read/write access to it and prevent race conditions.
Message Structure/Communication Format
The Store does not communicate over the network, so there is no message structure or communication format.
Assumptions and Considerations
The Store assumes that the underlying datastore is reliable and provides atomicity for transactions. It also assumes that the data passed to it for storage is valid and correctly formatted.
Implementation
See Store Interface and Default Store for its implementation.
References
[1] Store Interface
[2] Default Store
[3] Full Node Store Initialization
[4] Block Manager
[5] Badger DB
[6] Go Datastore
[7] Key Value Store
[8 ] Serialization